Beyond Fuzzy Match: How I Built a Hybrid Entity Resolution Pipeline
November 4th, 2025
NLP, semantic search, fuzzy match
When building relationships across datasets, the best approach is typically to use stable IDs. However, what do we do in the case that we do not have IDs? And even worse, what if the data we do have is entered by hand and inconsistent.
Problem definition
Consider the case where an external vendor gives you entity data, and you have to join it onto your own records. In my experience, we often work with external data vendors to enrich our records, and need a robust way to join the two. It would be nice if we had perfect join keys, but they are very rare given the constraints of data sharing. As such, we might intuit to use the titles of the entities (in my case HVAC dealers, and their company names) to join the records, however this presents several issues. The first is that the data from vendors might be scraped or hand entered, meaning that it came from the HVAC dealer's website and is unlikely to match, character for character, with our own records. The second issue is that entities can change the title between scrapes or data refreshes. HVAC companies update their names and get bought by private equity all the time. As such we need to use some other signal to match entity records across these datasets.
Location as a signal
Although their names might change, their location is unlikely to (though not impossible). So let's devise a plan that combines matching with both zip and name. Better yet, let's use a more flexible matching method than string matching alone: fuzzy match.
This is a good start. In our case, using fuzzy matching with concat(dealer_name, dealer_zip) as the join key, is a solid way to get up and running and to spot check the data that we buy. It also is easy to explain and intuitive to business stakeholders. However, it breaks down at scale.
A problem surfaces
If we think about how HVAC dealers are named, we can understand why this approach fails. For example the record for "Alice's Cooling" in our data could be "Alice's Refrigeration" or "Alice's HVAC" or any other number of combinations in other datasets, especially since many are entered by hand. Fuzzy match chokes on this because the distance between those letter combinations is so different. You might think that we could then drop the industry specific words like "HVAC", "heating", and "cooling", but then we lose too much signal from the original name.
Moreover, fuzzy matching on numbers like zip codes is highly problematic. There is no semantic understanding that two similar zips, say 51111 and 11111, are geographically close to each other. Instead, fuzzy matching algorithms like Levenshtein Distance or Jaro-Winkler just see that four of those digits are the same.
A better match
Instead, we keep the original name in full and combine the fuzzy match with a second method: embedding similarity. Unlike character-based distance metrics, embeddings capture the actual semantics of the text, so "Alice's Cooling" and "Alice's Refrigeration" end up close together in vector space where Levenshtein would see them as nearly unrelated. Concatenating the full address gives us strong, flexible signal even when names drift between datasets.
The final match score is a weighted average of the fuzzy and embedding scores, with embedding weighted higher because semantic similarity proved more robust to the name variation patterns we actually saw in the data. To tune the acceptance threshold, I used a binary search approach: starting at 0.5, I sampled 10 records above and below the threshold, passed them to an LLM, and asked whether each pair was reasonably the same company, the same judgment I'd make manually spot-checking. I halved the interval each iteration, checking 0.25, then 0.375, and so on, until the LLM-verified boundary stabilized at 0.29.
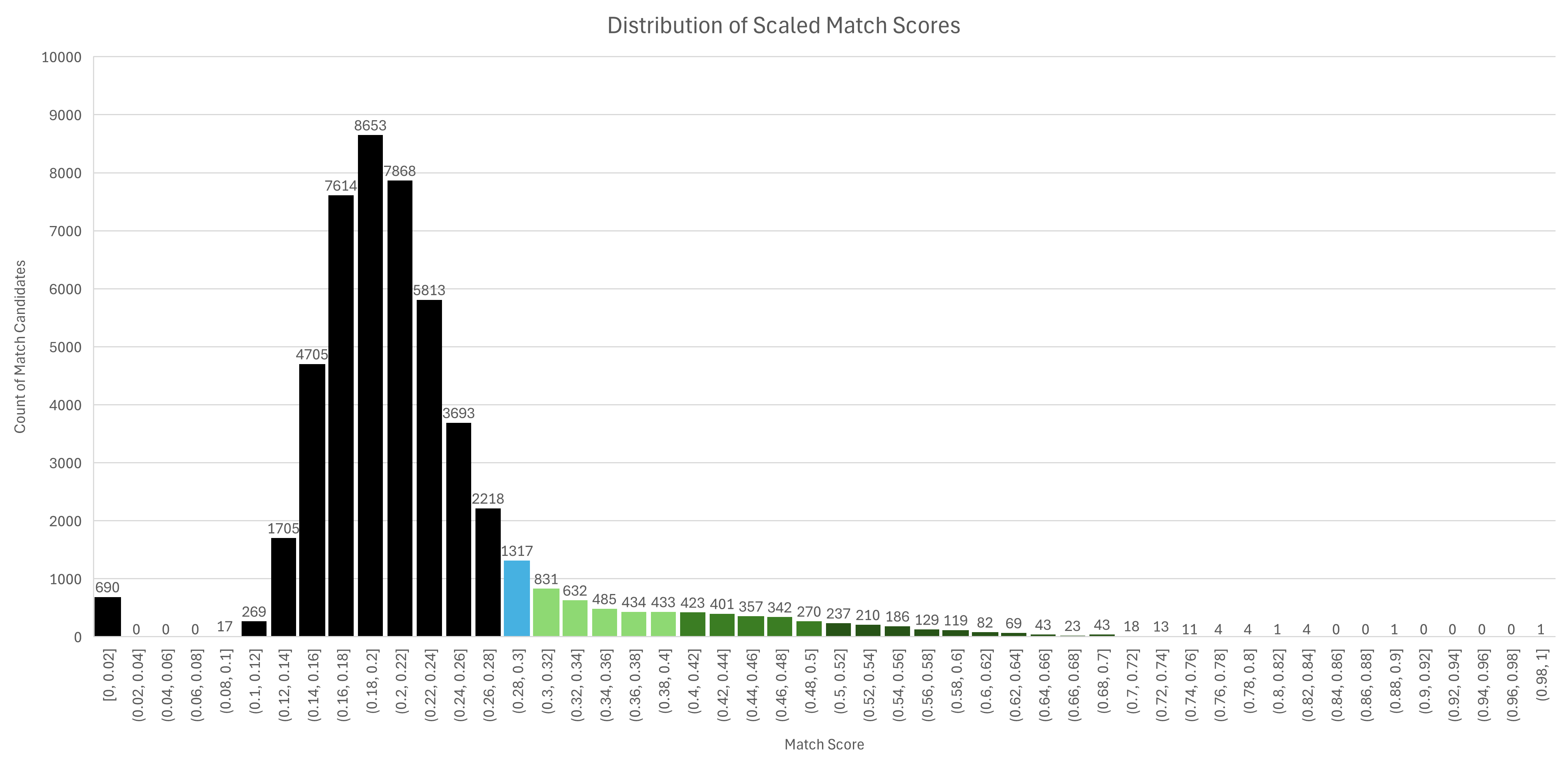
This gives the threshold tuning the same rigor as manual review, but at a fraction of the time and without the inconsistency of human judgment drift across hundreds of records. Against a dataset of ~50,000 HVAC dealers, the old fuzzy-only method matched 1,730 records (3.4%). The hybrid method matched 5,271 (10.5%), a 205% increase, with 4,318 of those being net-new matches that fuzzy alone never would have caught.