A Physics-based Approach to Temperature Upsampling
August 19th, 2025
geospatial modeling, data engineering, forecasting
The industry that I work in is influenced heavily by the temperature. As such, accurate measurement of temperature is crucial for driving business decisions. Below I will discuss my approach and methods to upsampling a cooling-degree-days dataset by NOAA from state-level metric, down to the 2.5 kilometer level, allowing for much more confident decision-making.
How fine is fine
State-level data would be adequate, if the weather didn't play such a key role in our business. It is crucial to get as fine-grained data as possible, but without spending money for commercial licenses, this data is very hard to come by. I figured I would take a stab at it using a free dataset from the National Oceanic and Atmospheric Administration (NOAA) that measures historical monthly cooling degree days (how many days the daily mean temperature rises above 65 degrees Fahrenheit) across all the states, and try to squeeze out as much as I can from it.
Temperature gradient
The first, naive approach I had was to simply create a temperature gradient between the states. So if the CDD for state A was 300 CDD for a given month, and state B (let's say it's directly adjacent) was 400 CDD for the same month, then we can just create a gradient between 300 and 400 for all the points between the two states.
This raises several questions. The first is how do you pick where to put the 300 in state A, is it the centroid of the state? The measure is presumably an aggregate, so do you locate all the measuring stations and calculate the centroid from those? No matter how you choose, it will be more or less arbitrary, but we will take steps later to account for that.
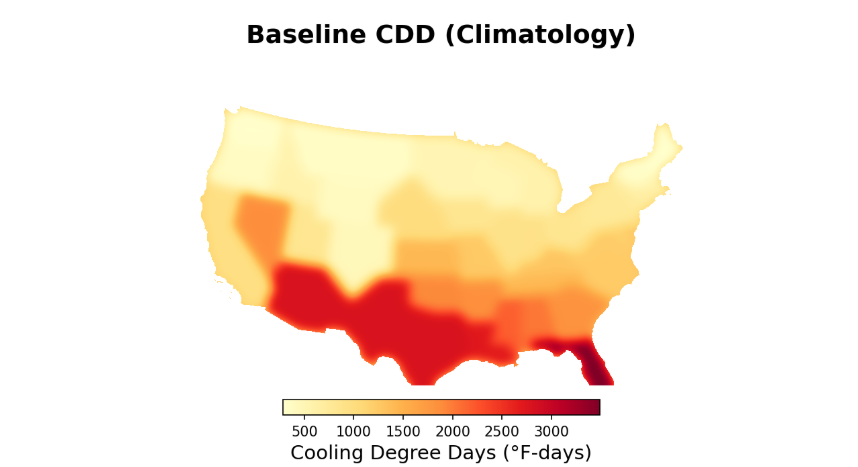
Next, what do we do about adjacency? Consider, for instance, Florida and Georgia in the above example. The high differential in CDD between the two states causes a steep gradient between them. While this is ok on a macro scale, on the country or zip level, this leads to highly inaccurate data.
So we see that a simple linear gradient between state centroids causes distortions and bias in measurements, but can we devise a better approach?
A naturally derived solution
Let's take a step back and study how temperature actually behaves. It is deterministically influenced heavily by several natural features, such as the topography, water bodies and even urbanization. We can stack these into many layers that define how the temperature actually permeates the geography of each state.
The way I intuited this is by imagining paint poured onto a map of the United States, one color per state, where the color represents that state's cooling degree days. The paint's fluidity lets it spread from each state's center and mix slightly with its neighbors, producing the smooth gradient we mentioned earlier. But if we alter the topography and texture of the map before pouring - raising or lowering it according to real physical features - the paint flows at different rates in different places, mixing in a way that's consistent with how temperature actually propagates.
In practice
We can take a very similar approach ourselves. By building a field of influence vectors, we can change how that initial state-level CDD value gets propagated down to smaller regions. We start with all the vectors at the same length, which represents that perfectly smooth map. Then we adjust the length of each vector by stacking different physically representative layers, like the altitude, the distance to the nearest water, the brush or tree cover, and many other features. This affects the magnitude of each vector, which in turn determines how the CDD signal propagates across the map.
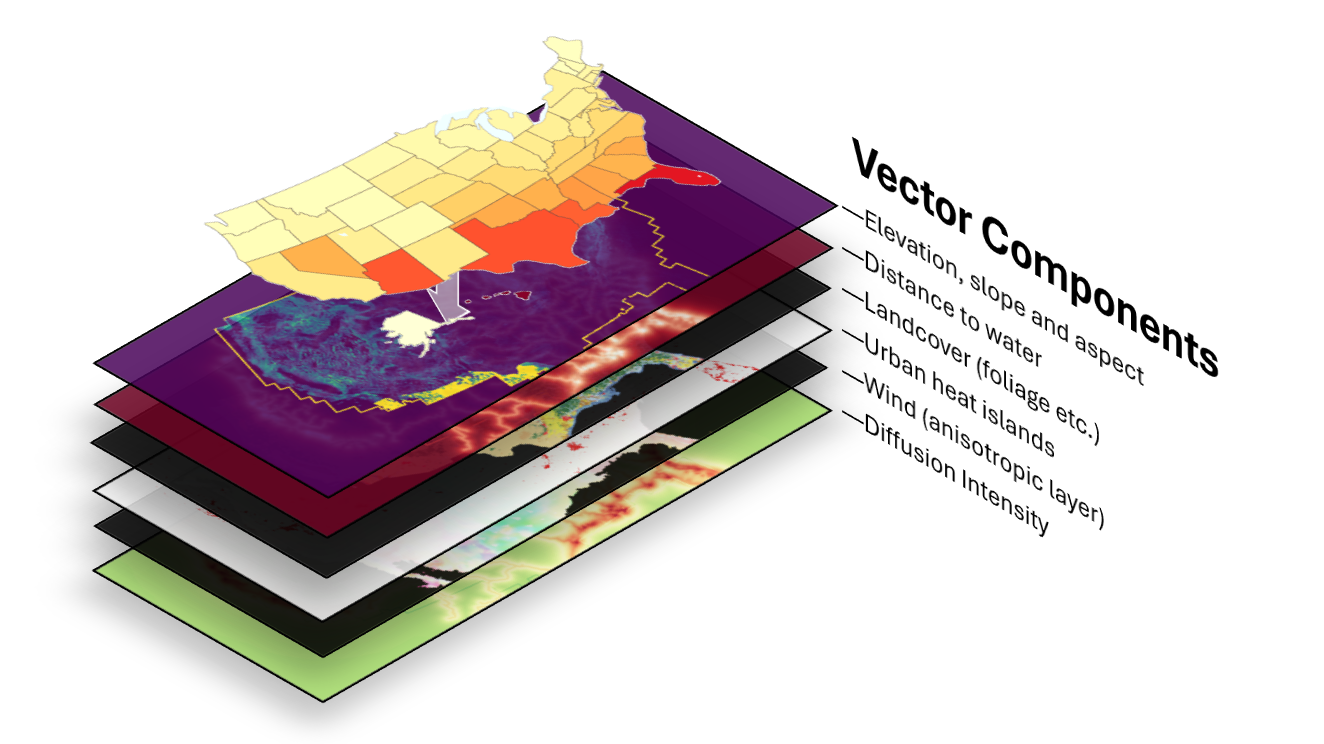
End-to-end workflow
Putting this all together: I start from state-level CDD forecasts and historical climate baselines, and lay them onto a common national grid so everything lines up geographically. Then I layer in the physical drivers - elevation, slope, distance to water, land cover, urbanization - and convert those into a conductivity surface that controls how strongly heat anomalies spread from one area to the next. Each state gets seeded with its own anomaly signal, which then diffuses across the map so neighboring areas influence each other naturally instead of stopping dead at a state line. I keep the original state forecasts as soft anchors rather than hard constraints, so the final map stays realistic without straying too far from the broader forecast. From there, I recompose the local CDD values and aggregate them up to ZIP, county, and MSA level for downstream forecasting.
How this drives forecasting decisions
The practical value here is that it turns a single state-level weather signal into local demand risk. Instead of saying "Texas is hot this year," we can point to the specific ZIPs and MSAs likely to carry the highest cooling burden, and therefore the highest pressure on installed HVAC systems.
At a planning level, that feeds into where we stage inventory and service capacity ahead of peak demand, which regions are likely to see a spike in replacement activity versus routine service, and how we prioritize sales, dealer support, and marketing spend by local opportunity rather than blunt state averages.