Building a RAG-Based SQL Agent on Messy Enterprise Data
April 16th, 2026
NLP, cloud, enterprise, LLM, agentic AI
Often architected before the AI era by multiple architects over many years, it takes substantial effort to build clean, LLM ready data, especially without breaking existing pipelines. Beyond this, while powerful at general tasks, LLMs often stumble over internal jargon, vocabulary, and definitions. In this project, I propose a solution for all of these issues.
The context problem
When architecting an analyst agent on enterprise data, LLM context limits constrain how much you can actually process at once. RAG is the natural solution, but it breaks down with tabular data - so instead, we let the agent write SQL, retrieve results, and use them as the basis for analysis. The problem is that out-of-the-box, the agent expects clean, well-documented data. Without proper guidance on your specific schema, join keys, and domain rules, it will stumble and hallucinate. So how do we provide that guidance at scale?
A two pronged approach
In breaking down this issue, I defined two sub-issues which guided the planning. The first of these is the response usefulness. Can the agent understand what you are asking? Does it understand your internal business jargon and definitions? The second is response accuracy, specifically in the returned data. Even if it understands what you are asking, can the agent actually find the correct data to answer your query?
There are several things required to give an AI agent proper context of your data and its role. In general, the idea is to give the agent a sort of knowledge bank to draw from when providing answers, almost like an employee handbook. It needs to know all of the jargon that the organization's members know, all of that jargon that wasn't used in the LLM's training data but is crucial for providing useful answers.
My first approach was to build this by hand. I made a table in our database which included several business terms, their definitions, synonyms and some other metadata. The contents of this table were included by being appended to the bottom of the user prompt. Sure, this helped make the answers from the agent more useful, but this human-written context-injection approach was highly error-prone and it risked introducing bias in the domain knowledge excluded through oversight.
Next, before writing any SQL, the agent needs more context about the data itself. It needs to know all of the ins and outs of the data, the required joins, the specific table names, the actual formulas used to calculate specific pertinent values. The agent needs some examples of querying your data, a prompting technique known as few-shot generation. This helps to direct the agent's output towards more correct results. We call this list of examples our "validated query repository." This repo is injected directly into the prompt so the agent always has a recent reference to it. However, manually building a custom business glossary is a lot of work. Gaps in personal knowledge produce gaps in the LLMs knowledge and traditional semantic layering doesn't provide enough signal to ward off hallucinations. Looking forward, data discovery must also be documented and maintained for future sources in order to guarantee a robust product.
The search for signal
So, where can we find sufficient signal for the semantics of our data that we can use to generate a knowledge base for the agent to use? Employees' internal communications would technically carry that signal, but scraping emails and chat messages between employees was never a real option - it disregards privacy and wasn't seriously considered. Instead, we landed on the account_usage.query_history table in our databases.
The idea is very simple: query that account_usage.query_history table where there are strings that match the comment syntax of SQL and that are longer than some threshold, say 300 characters. We take the full list of queries and group them by the table that they are actually selecting data from, then we feed that whole list into an LLM, and ask it to derive as much organization specific vocabulary from it as it can. In spot checks against the source queries, it consistently extracted correct formulas and definitions, automatically building that business glossary and solving our first sub-issue - a more systematic accuracy eval is still on the roadmap.
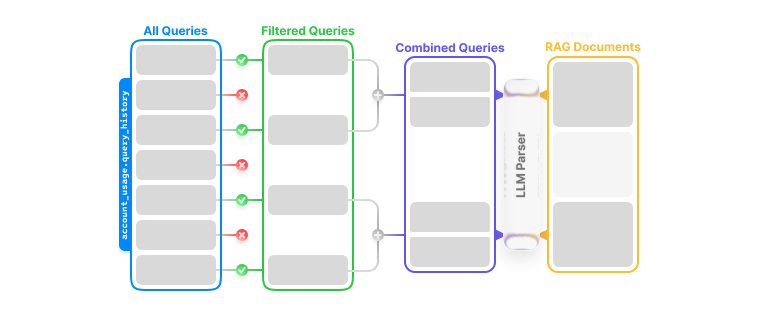
And elegantly, we do nearly the exact same to build the validated query repository. The difference here is that instead of instructing the LLM to extract vocabulary, we ask for a unified query that spans the queries it saw as examples.
Finally, in the agent loop, we simply use text embeddings to pass the business glossary entries contextually as needed. The validated queries, however, we pass all at once. I found that giving the agent the full repo, rather than trimming it down, meaningfully improves its ability to join tables and build queries that span multiple sources. That tradeoff is easy to make today: with frontier models routinely offering context windows over 1M tokens, spending a few thousand tokens on the query repo barely moves the needle.